
”Hive 小表join大表优化“ 的搜索结果
1)小表Join大表 将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用Group让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。 select ...
hive大小表join优化性能
标签: hive
摘要: MAPJOIN 当一个大表和一个或多个小表做JOIN时,最好使用MAPJOIN,性能比普通的JOIN要快很多。 另外,MAPJOIN 还能解决数据倾斜的问题。 MAPJOIN的基本原理是:在小数据量情况下,SQL会将用户指定的小表全部...
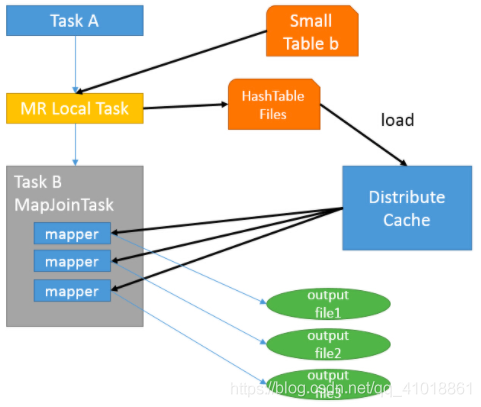
join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。这里的join会在map阶段完成,仅仅是在内存就进行了两个表的join,并不会涉及reduce操作。map端...
如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题。首先引入一个具体的问题场景,然后基于此介绍各自优化方案。 5.1、问题场景 问题场景如下: A表为...
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。3.1、空key过滤。

如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题。首先引入一个具体的问题场景,然后基于此介绍各自优化方案。 5.1、问题场景 问题场景如下: A表为...


一、SQL本身的优化 1、只select需要的列,避免select * 2、where条件写在子查询中,先过滤再关联 3、关联条件写在on中,而不是where中 4、数据量大时,用group by代替count distinct 5、数据量小时,用in代替join 6...

hive-大表Join的数据偏斜 hive—大表Join的数据偏斜 大表Join的数据偏斜 MapReduce编程模型下开发代码需要考虑数据偏斜的问题,Hive代码也是一样。数据偏斜的原因包括以下两点: Map输出key数量极少,导致reduce端...
hive大表join空key优化
标签: hive
hive大表join空key优化如果A表中有大量c字段为null的数据。如果不对null值处理,此时,会产生数据倾斜!情形一情形二 如果A表中有大量c字段为null的数据。如果不对null值处理,此时,会产生数据倾斜! 情形一 假如...
用户轨迹工程的性能瓶颈一直是etract_track_info,其中耗时大户主要在于trackinfo与pm_info进行左关联的环节,trackinfo与pm_info两张表均为GB级别,左关联代码块如下: [SQL] 纯文本查看 复制代码 fr...
1. Join的基本原理大家都知道,Hive会将所有的SQL查询转化为Map/Reduce作业运行于Hadoop集群之上。在这里简要介绍Hive将Join转化为Map/Reduce的基本原理(其它查询的原理请参考这里)。假定有user和order两张表,分别...
大类1:参数优化 文件输入前看是否需要map前合并小文件 控制map个数,根据实际需求确认每个map的数据处理量,split的参数等 Map输出是否需要启动压缩,减少网络传输,OOM处理等 控制redcue个数,控制每个reduce...
经常看到一些Hive优化的建议中说当小表与大表做关联时,把小表写在前面,这样可以使Hive的关联速度更快,提到的原因都是说因为小表可以先放到内存中,然后大表的每条记录再去内存中检测,最终完成关联查询。...
和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦。 首先介绍大表join小表优化。以销售明细表为例来说明大表...
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。 Hive0.7之前,需要使用hint...
案例一: select a.id,a.number,b.number,c.number from table_tmp a join table_tmp b on a.id = b.id ...如上例中,Hive会对每对join连接对象启动一个MaoReduce任务。首先启动一个MapReduce job对表a和
select /*+ MAPJOIN(time_dim)*/ count(1)fromstore_salesjointime_dimon (ss_... b.y 或者 a.x like b.y等)这种操作如果直接使用join的话语法不支持不等于操作,hive语法解析会直接抛出错误如果把不等于写到where里...
将key相对分散,并且数据量小...实际测试发现:新版的hive已经对小表JOIN大表和大表JOIN小表进行了优化。小表放在左边和右边已经没有明显区别。 案例实操 测试大表JOIN小表和小表JOIN大表的效率 1、建大表、小表和...
众所周知,hive 提供了三种join方式,common join/map join/ smb join,那么如何选择最合适的join 类型?1. common join是最常见的join 类型,需要执行shuffle操作,根据join条件对数据进行重新分布,shuffle操作...
经常看到一些Hive优化的建议中说当小表与大表做关联时,把小表写在前面,这样可以使Hive的关联速度更快,提到的原因都是说因为小表可以先放到内存中,然后大表的每条记录再去内存中检测,最终完成关联查询。...

left join,right join,inner join,full join之间的区别 参考 备注:转载的 转载地址:https://www.cnblogs.com/lijingran/p/9001302.html 下面是转载内容 https://www.cnblogs.com/assasion/p/7768931.html ...
hive 大小表mapjoin 遇到udf失效问题 执行结果有三个重要信息: /tmp/liangxin/liangxin_20201026173636_ddccc70a-1019-49d4-9cc8-6b072023187a.log Stage-4 /tmp/liangxin/hive.log 问题分析: 打开第一...
一、小表、大表 Join 将 key 相对分散,并且数据量小的表放在 join 的左边,这样可以有效...新版的 hive 已经对小表 JOIN 大表和大表 JOIN 小表进行了优化。小表放在左边和右边已经没有明显区别。 例: 1、创建大...
推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地